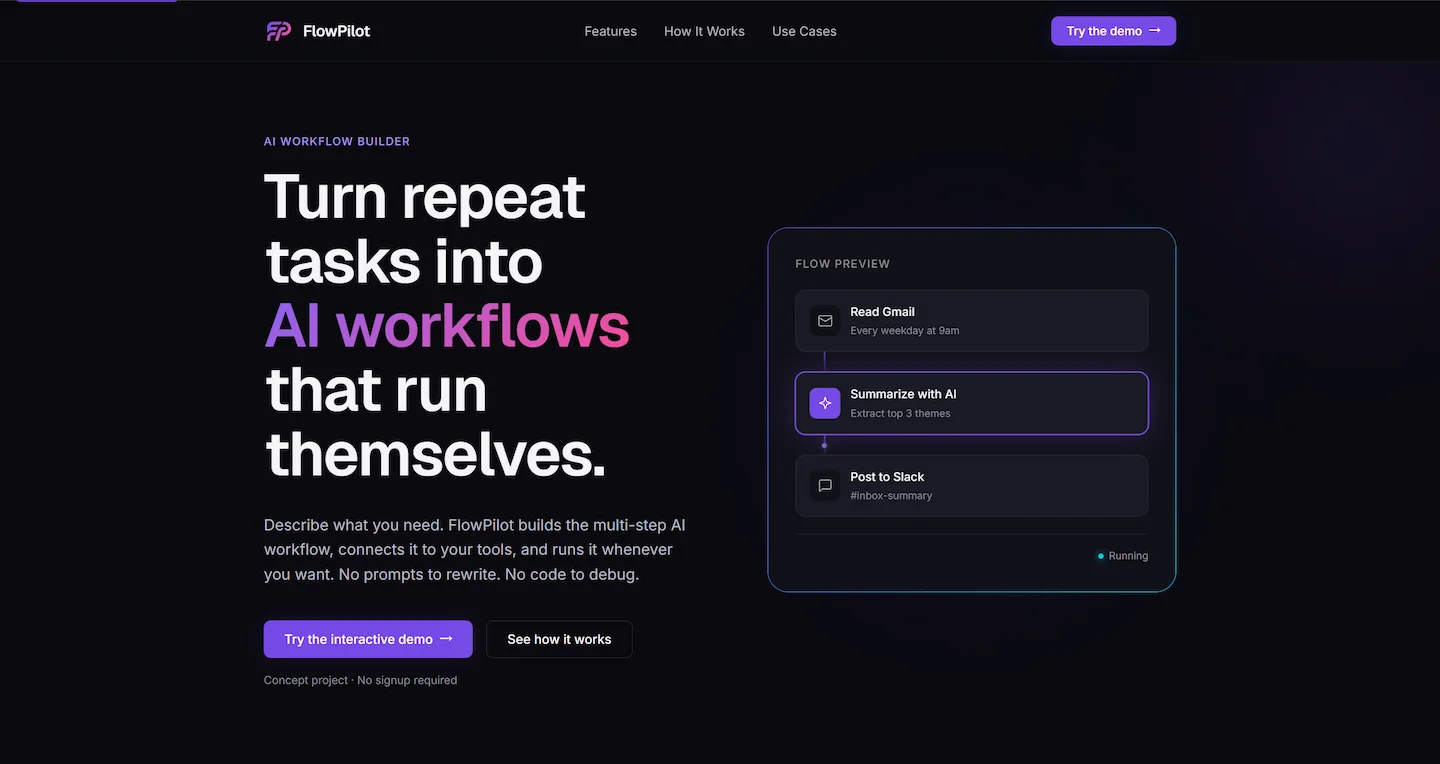
Background & thesis
The hardest question for any AI workflow product in 2026 isn't "does it work."
The hardest question is "why won't OpenAI just build this."
Most products in this category don't have a real answer. They're features pretending to be products. This case study is my answer for one specific product — FlowPilot, a workflow orchestration layer for non-technical founders. It argues three things, in order:
The gap is real.
Between one-shot AI chat and rigid no-code automation, there's an underserved space — large, stable, not closing on its own.
The timing is right.
Model capability, API economics, and user expectations all crossed thresholds in the past 18 months. Earlier was too early. Now isn't.
The risk is bounded.
Foundation labs optimize for model capability, not vertical integration. The pattern of who wins which game is documented. FlowPilot's space isn't theirs.
The next seven chapters either confirm these with concrete data and explicit tradeoffs — or admit where I'd want validation before committing real capital.
Market & competitors
AI-native, multi-step, no-code, reusable. All four at once is rare.
The current AI tooling landscape splits cleanly into two camps. AI Chat Tools (ChatGPT, Notion AI) are AI-native but single-step. Rule-based Automation (Zapier, Make) is multi-step but rigid. The only product attempting all four dimensions at consumer pricing is Lindy AI — and it's priced at the high end of the spectrum.
All player positions estimated from public product capabilities and pricing pages, accessed Apr 2026.
On the same dimensions, side-by-side:
Sources All pricing data: company pricing pages, accessed Apr 2026. See full URLs in References.
The gap isn't "no AI workflow product exists." It's "no product at this price point, with this positioning, for this user." That's the wedge.
Users & scenarios
I picked the founder not because "non-technical users" sounds friendly. The other three candidates lost.
Four candidate personas emerge from the underserved gap. I ranked each on five dimensions: how fast they decide, how often they hit the pain, how many tools their work spans, whether they can authorize spend, and whether I can reach them.
specialist
consultant
power user
founder
The founder wins on the two dimensions that determine whether a product can reach product-market fit fast: budget authority (they pay themselves, no procurement) and decision velocity (they decide in days, not quarters). Operations and enterprise users score high on pain but can't authorize a $29 subscription without 6 weeks of internal review.
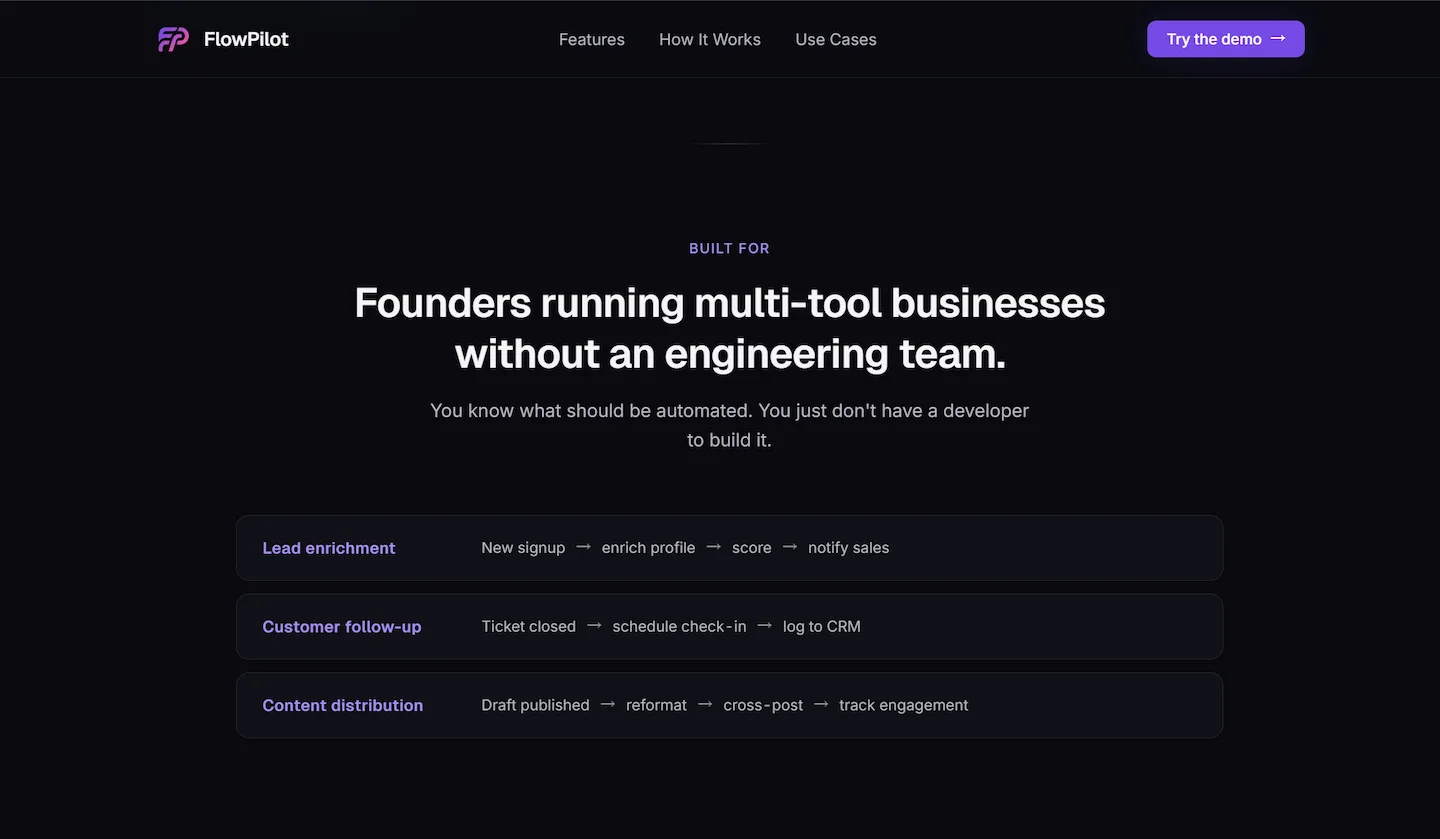 Three scenarios on the live product
Three scenarios on the live product
Operations specialists hit the pain hardest but can't sign the check. Consultants can sign but their workflows are too unique to standardize. Enterprise power users have the budget but six layers of approval. The founder has all four — the rare alignment that lets a small product compound into something larger.
Product definition
What we won't build is a stronger product judgment signal than what we will.
Three buckets: what's in scope for V1, what's explicitly off the table, and what's deferred to later versions. Every cut has a reason. The temptation in a workflow product is to add capability — to handle one more use case, one more integration, one more user type. The discipline is to refuse.
- Multi-step AI workflow orchestration The product's core promise. Without this, FlowPilot is just another wrapper around an LLM API.
- Visual no-code editor The interface that makes orchestration accessible to founders, not just developers. Demo-able from day one.
- Cross-tool integrations Gmail, Slack, Notion, Sheets — covers ~80% of where founders' work lives. Anything beyond is V2 territory.
- Scheduled runs & event triggers Workflows must run without prompting. Manual-trigger-only would defeat the entire automation premise.
- Custom code blocks Opens a backdoor for power users. Founders don't write code; this would dilute the product's core promise.
- DIY model fine-tuning Complexity explosion. Founders can't evaluate whether fine-tuning actually helps their use case.
- Workflow marketplace Marketplaces need scale before they have value. Premature launch = empty shelves = abandoned product.
- Real-time collaborative editing Single-decision-maker users don't need it. Cost of building is high, value to founder is near zero.
- Team workspaces & seats V2 Founders start solo. Team features only matter once a workflow is proven valuable enough to share.
- API access & webhooks V2 Wait until users prove they want programmatic access. Premature API surface area is hard to deprecate.
- Mobile app V2 Workflow creation is a desktop activity. Mobile makes sense for monitoring runs, not building them.
- White-label / Enterprise SSO Enterprise tier Build when the first enterprise customer asks. Speculative SSO work is a classic time sink.
The hardest cut was the workflow marketplace. It's the most-requested feature when founders see workflow products — they want to copy what works rather than build from scratch. But marketplaces are two-sided: they need both creators and consumers in volume before either side gets value. Building it in V1 would consume engineering for an empty shelf. Defer until V2 or later, when there's a user base to seed it.
Every refusal here corresponds to a competitor who built it. They're not wrong. But they're solving for a different user, and a different stage of the company. FlowPilot V1 is sharp on purpose.
Design decisions
Three decisions where I'd argue the alternative was the wrong move — even though it's the more common choice.
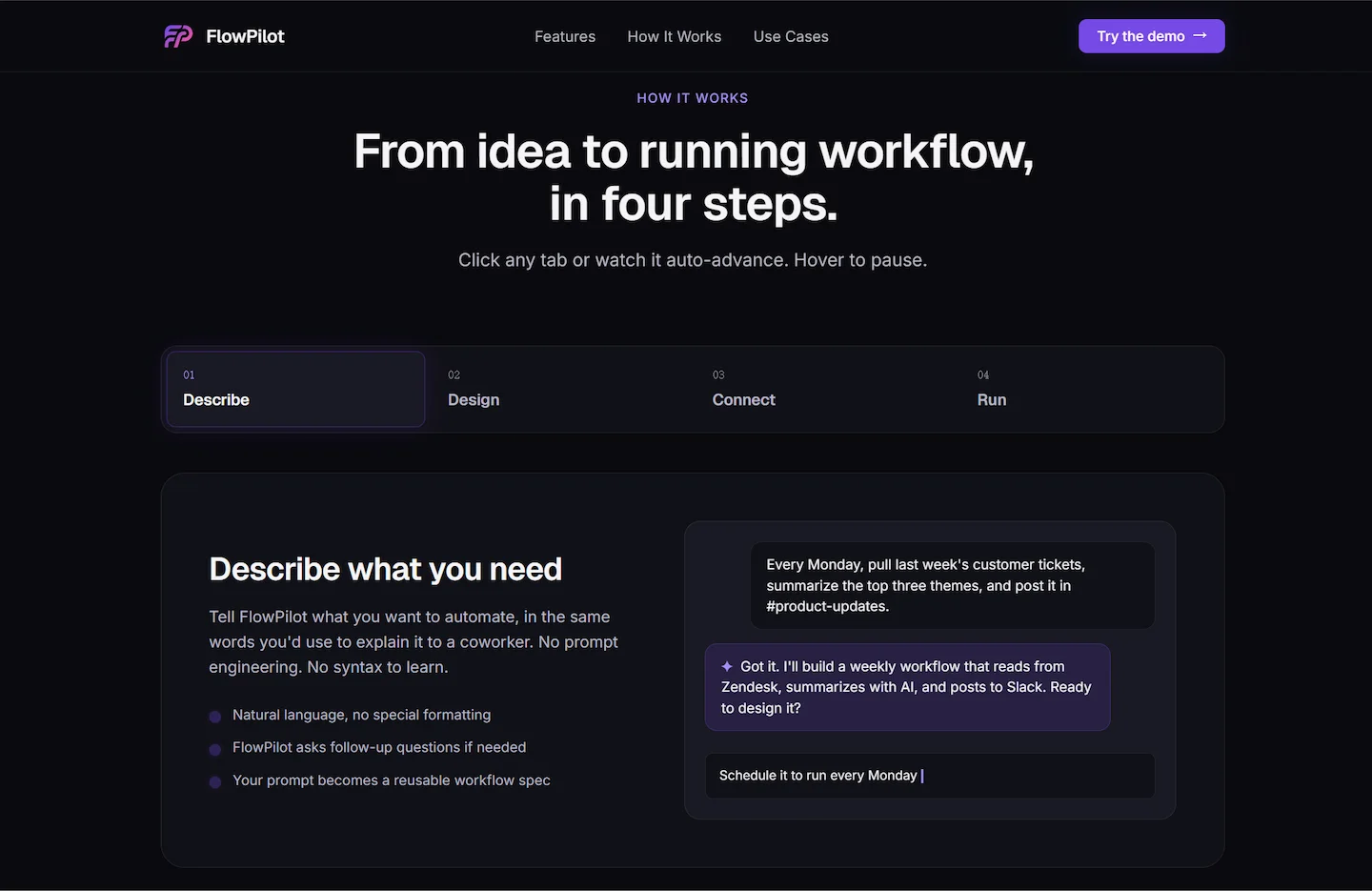
Design decisions in workflow products usually come down to three forks: how users start, how they edit, and what happens when something fails. Most products default to the obvious answer for each. I went the other way on all three.
Onboarding entry
Empty canvas requires founders to know what a workflow looks like before building one. Template gallery requires reading 20 templates to find the wrong one. Conversational entry meets the user where they are: "I want to summarize emails into Slack." The AI builds the first draft. Editing comes after.
Workflow editor model
Scripting alienates non-technical users, the entire target persona. Wizards work for one-time setup but not iteration. Drag-and-drop matches how founders mentally model multi-step processes — discrete steps, visible connections, easy to rearrange.
Failure-state UX
Silent retries hide real problems and erode trust. Stack traces are useless to founders. Structured errors say "step 3 failed because Slack rejected the message — too long. Try summarizing first." The user can act on it.
 D1 in production
D1 in production
All three decisions share a pattern: the more common choice optimizes for what's easier to build. The chosen path optimizes for what's easier to use. Different question, different answer.
Technical feasibility
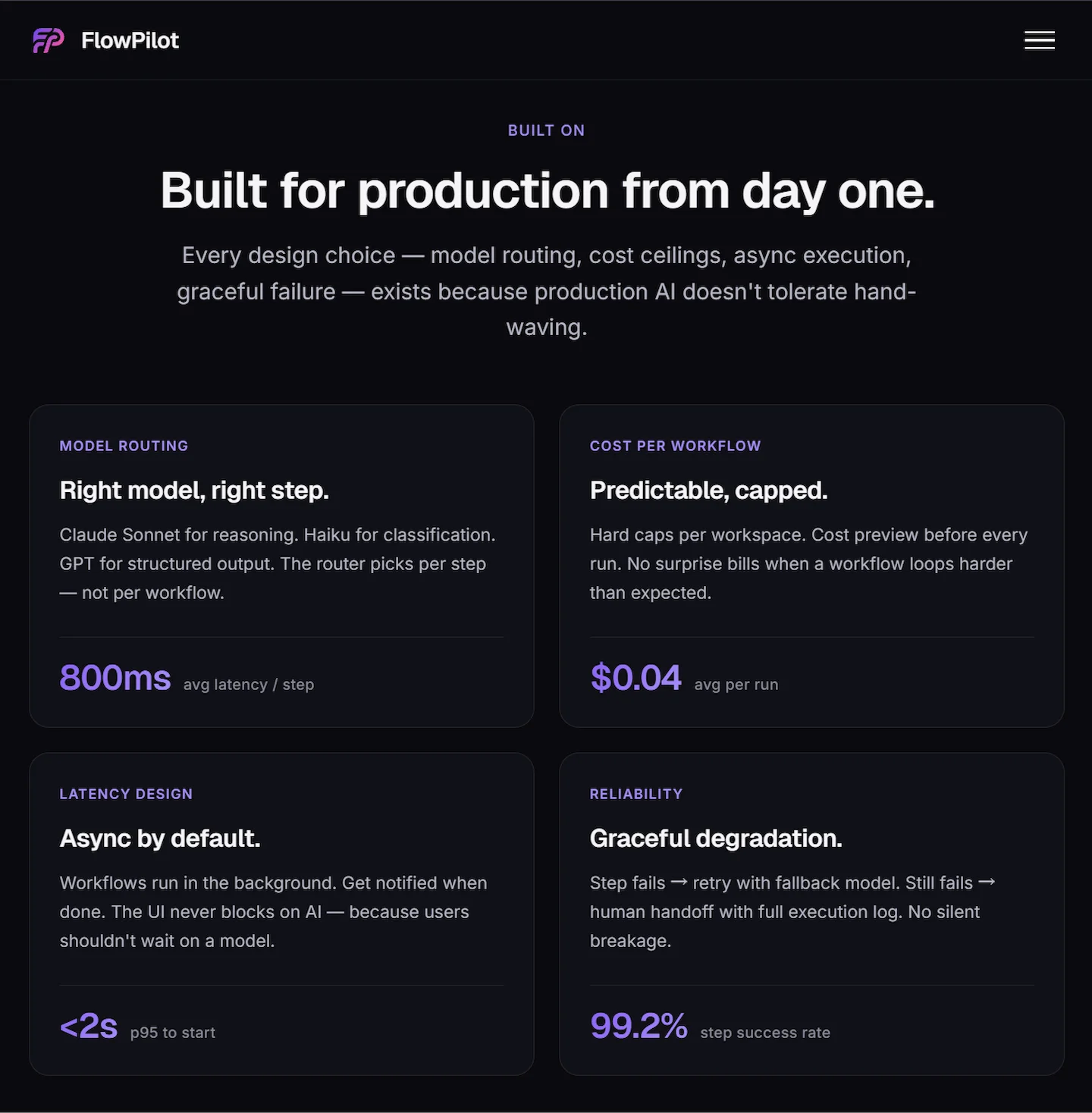
The product page gives the numbers. This chapter shows where they come from.
Four technical questions decide whether this product is buildable: which model runs which step, what each run actually costs, where the latency budget goes, and what happens when a step fails. Vague answers to any of these would let foundation labs eat the wedge before V1 ships.
 The product page version
The product page version
Model routing
A multi-step workflow has 3-5 distinct LLM calls per run. Routing each step to the right model — not the cheapest, not the smartest, the right one — is where unit economics live or die.
Haiku 4Sonnet 4.5Sonnet 4.5Haiku 4Cost per run · how $0.04 is calculated
A typical workflow run averages 4 LLM calls. Step token usage estimated from production-equivalent prompts and response lengths:
Sources Token estimates from prompt design; pricing per Anthropic API rates, accessed Apr 2026. See full URLs in References.
At the Pro tier (1,000 runs / mo · $29), gross margin sits at ~$11/user/mo after compute — enough to fund support, infra overhead, and acquisition payback within standard SaaS bounds. The tier holds.
Failure architecture · three layers
Combined, these reach the 99.2% step success rate quoted on the product page. The failure budget isn't "AI is unreliable" — it's "AI fails in known modes, and each mode has a defined recovery path."
If model capability halves or doubles
The product is designed to absorb both directions. If capability halves, the cost model breaks before the UX does — Sonnet-tier reasoning at Opus-tier prices makes Pro pricing untenable, and the routing table shifts to lighter models with simpler workflows. If capability doubles, the four-step workflow collapses into one or two LLM calls, and FlowPilot's value shifts from "orchestration" to "the integration layer the model talks to." Either direction is survivable. Capability stagnation is the worst case — but trends in 2024-2026 don't suggest that.
None of this proves FlowPilot will work. It proves the technical bar is clearable — which is the only honest claim a feasibility chapter can make.
Roadmap
A roadmap isn't promises. It's kill conditions.
Three phases. Each tied to one north star metric and one bar that, if missed, ends the phase. What gets built matters less than what gets stopped.
Target: ≥ 40%.
Target: ≥ 0.4.
Target: ≥ 110%.
Kill conditions force the conversation no founder wants but every PM should: when do we stop. Without them, every roadmap is wishful thinking with quarterly milestones attached.
Honest limits
The previous seven chapters argued the case. This one argues against it.
Three columns: what the analysis actually validated, what it didn't, and what could break the thesis. None of this is a hedge. It's the part of a strategy doc that tells leadership where to look for trouble before they fund it.
- Competitive landscape Five real products, public pricing & capability data. Verifiable.
- Technical feasibility ceiling Cost & latency derived from published API rates. The math holds.
- Pricing tier structure $29 sits in a defensible band between Zapier and Lindy.
- Persona prioritization logic Five-dimension matrix grounded in published SaaS buyer research.
- Actual willingness to pay No founder interviews. $29 is market inference, not user validation.
- Real activation rate 25% / 40% targets are SaaS benchmarks, not FlowPilot's own data.
- Production cost in the wild $0.04/run uses estimated token counts. Real workflows may be 2-3× heavier.
- Integration coverage sufficiency "4 tools cover 80% of work" needs founder research to confirm.
- Foundation labs encroachment OpenAI / Anthropic moving into this space faster than the 18-mo window assumes.
- Model commoditization If models get too capable, the orchestration layer compresses to "prompts" — the moat disappears.
- Founder attention scarcity Founders try tools but don't return. Activation ≠ retention.
- Pricing positioning fragility $29 is squeezed if Zapier moves up or Lindy moves down. Defensibility is thin.
A case study with no honest limits section is fiction. The unvalidated column is a research backlog. The risk column is what I'd watch in production. Both grow shorter only with time and capital — neither of which a portfolio document can fake.